Part 3: How to Fix Your GPU Utilization

Debo Ray
Co-Founder, CEO

This is a 5 part series on why GPU clusters are under-utilized, how to measure utilization and how to improve it.
Part 1 - Why is your GPU cluster idle
Part 2 - How to measure your GPU utilization
Part 3 - How to fix your GPU utilization
Part 4 - GPU security and Isolation
Part 5 - Tips for optimizing GPU utilization in Kubernetes
How to fix your GPU utilization#
Different ML workload types require fundamentally different optimization approaches. A strategy that works well for training workloads may be counterproductive for real-time inference, and vice versa.
Training Workload Optimization#
Training workloads benefit from checkpoint/restore strategies that enable more aggressive use of cost-effective compute options. By implementing robust checkpointing, organizations can:
- Use spot instances for training workloads, reducing costs by 60-80%
- Implement automatic job migration during node maintenance
- Enable faster recovery from hardware failures
- Support more efficient cluster scheduling through workload mobility
Node selection strategies for training workloads should prioritize cost-effectiveness over availability. Training can tolerate interruptions with proper checkpointing, making spot instances and preemptible nodes attractive options.
Real-Time Inference Optimization#
Inference workloads require right-sizing strategies that balance resource efficiency with performance requirements. Key optimization principles include:
Memory-based right-sizing: Match GPU memory capacity to model requirements rather than defaulting to the largest available instances. An 80GB model doesn't require a 141GB GPU unless you plan to utilize specific optimization techniques or anticipate future model growth.
Replica optimization: Determine the optimal number of inference replicas based on request patterns, cold start costs, and resource utilization. More replicas reduce individual utilization but may improve overall efficiency by minimizing the number of cold starts.
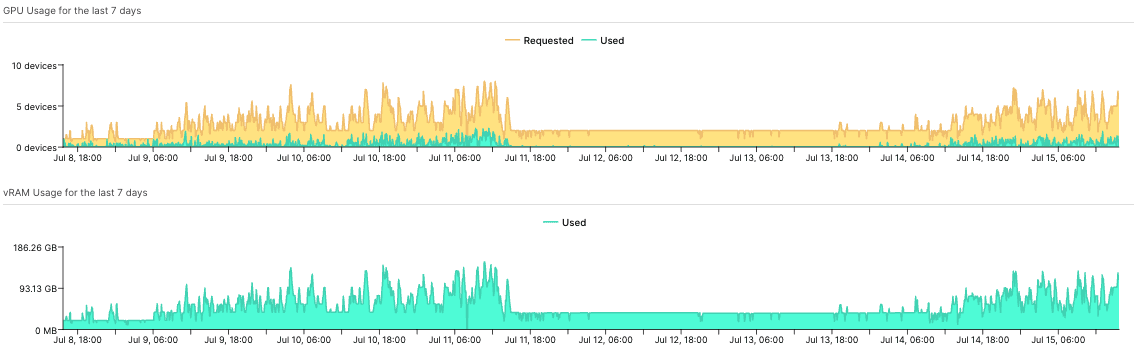
While still not completely optimized, horizontal autoscaling helps this workload not overprovision for the sparse peaks
Resource sharing for compatible workloads: When multiple inference workloads have complementary usage patterns, GPU resources can be shared effectively. Two inference services, each requiring 60GB of GPU memory but with sparse actual utilization, can potentially share a single H100 with 141GB of memory.
Advanced Resource Sharing Strategies#
Modern GPU architectures enable sophisticated resource sharing strategies that can dramatically improve utilization:
Multi-Instance GPU (MIG) technology allows hardware-level partitioning of NVIDIA A100 and H100 GPUs into smaller instances. This enables multiple workloads to share a single physical GPU with hardware-level isolation, improving utilization while maintaining security boundaries. More about MIG and GPU multi-tenancy here.
Time-multiplexed sharing works well for workloads with different usage patterns. A training workload that runs overnight can share GPU resources with inference workloads that peak during business hours.
Memory-based sharing enables multiple workloads to coexist on the same GPU when their combined memory requirements fit within available GPU memory and their compute usage patterns don't conflict.
The Hidden Costs: Ancillary Workload Optimization#
GPU workloads rarely operate in isolation. They depend on CPU-intensive preprocessing, network data transfer, and various supporting services that can create bottlenecks and reduce overall GPU utilization efficiency.
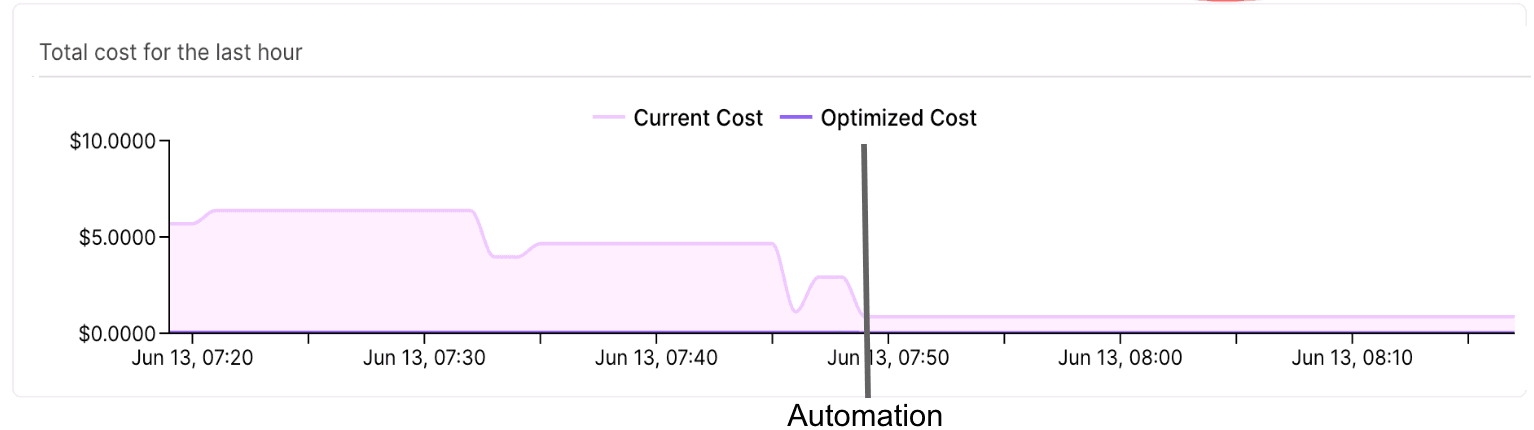
Impact of optimization automation on cost
CPU Preprocessing Bottlenecks#
Many ML workloads include significant CPU-intensive preprocessing steps that can starve GPU resources. Data loading, image preprocessing, and feature engineering tasks often run on CPU cores while GPUs wait for processed data.
Strategic CPU allocation for GPU workloads involves:
- Right-sizing CPU resources to match GPU processing capacity
- Implementing preprocessing pipelines that minimize GPU idle time
- Using CPU-optimized preprocessing libraries that maximize throughput
- Considering preprocessing acceleration through specialized hardware
Network and Storage Considerations#
GPU workloads often involve substantial data movement that can impact utilization efficiency. Model loading, dataset transfer, and result output can create I/O bottlenecks that reduce GPU efficiency.
Network optimization strategies include:
- Selecting nodes with appropriate network interface capabilities
- Implementing efficient data pipeline architectures
- Using content delivery networks for model and dataset distribution
- Optimizing data formats and compression for faster transfer
Storage optimization involves:
- Using high-performance storage for model and dataset access
- Implementing caching strategies that reduce repeated data loading
- Considering local storage for frequently accessed models
- Optimizing model serialization formats for faster loading
Sidecar Container Optimization#
GPU workloads often include supporting containers that handle API endpoints, networking, monitoring, and other auxiliary functions. These sidecar containers can consume significant CPU and memory resources if not properly optimized.
Common sidecar patterns include:
- FastAPI containers serving inference endpoints
- Istio service mesh components for networking and security
- Monitoring and logging agents for observability
- Authentication and authorization services
Sidecar optimization strategies focus on:
- Right-sizing sidecar resources based on actual usage patterns
- Consolidating multiple sidecar functions where possible
- Using lightweight alternatives for non-critical functionality
- Implementing resource sharing between primary and sidecar containers
**Join this upcoming workshop with NVIDIA to learn more about GPU utilization for Kubernetes. **Register here.

Debo Ray
Co-Founder, CEO






