Karpenter vs. Cluster Autoscaler: How They Compare in 2025

Alberto Grande
Head of Marketing

Every few years, a new project shows up that causes the Kubernetes ecosystem to rethink the operations mental model.
In 2018, I was helping a company tame a three-hundred-node cluster with Cluster Autoscaler (CA). Just by using CA, the company saved thousands of dollars a month by pruning idle nodes.
CA was helping a lot of customers, but it had a few challenges. Then, in 2021, Karpenter was released — the new kid in the block for Kubernetes autoscaling. Suddenly, CA wasn’t the only option.
Fast-forward to today, and both projects are mature enough to run production traffic. They just solve the scaling puzzle from two different perspectives. While CA optimizes inside the constraints of predefined node groups, Karpenter is more flexible and redraws the picture every scheduling cycle.
With all this in mind, let’s walk through what that means in practice, where each one shines, and how DevZero plugs the gaps none of the open-source tools even attempt to address.

Horizontal Pod Autoscaling Is the Foundation#
Before diving into where Karpenter and Cluster Autoscaler fit, it's very important that you understand where the Horizontal Pod Autoscaler (HPA) enters into the picture, since it works hand-in-hand with both tools.
HPA operates at the workload level, automatically adjusting the number of pod replicas in a deployment, replica set, or stateful set based on observed metrics like CPU utilization, memory usage, or custom metrics.
However, HPA only manages the number of pods; it doesn't provision new nodes. If there isn't enough capacity in your cluster to schedule the additional pods that HPA wants to create, those pods remain in a "Pending" state.
This is where node-level autoscaling becomes essential. HPA creates more pods, while Cluster Autoscaler or Karpenter responds by provisioning the underlying infrastructure to host those pods. HPA handles application scaling, while node autoscalers handle infrastructure scaling. So, with that in mind, let’s continue.
What Is Cluster Autoscaler, and How Does It Work?#
Cluster Autoscaler is a cluster autoscaling solution that has been the default answer for node fleet management since 2016. It watches for pods that the scheduler marks unschedulable then resizes the underlying node group like an AWS Auto Scaling Group, GKE managed instance group, Azure VM scale set, or plain cloud-provider API to fit the demand.
CA’s design choices feel conservative in the best sense of the word. Why? Because it:
- Trusts the cloud provider to know which instance type to launch
- Works only inside node groups you describe up front
- Waits for configurable cool-down timers before scaling down
- Has knobs for every corner case imaginable to tune the balance between cost, performance, and availability
That caution kept many companies afloat through pandemic traffic spikes, but it also hardcodes yesterday’s assumptions: a node group is homogeneous, nodes launch quite slowly, and the price you pay per core might be predictable (if not using too many different instance types; we’ll talk about this later).
What Is Karpenter and How Does It Work?#
Karpenter rips out CA’s assumptions. Instead of stretching or shrinking groups, it opens the entire EC2 (or whichever compute service provider) catalogue on every pass. The controller batches pending Pods, solves their collective constraints — like CPU, memory, taints, topology spreads, and capacity type — and fires a single API call to grab the cheapest instance that fits . When the batch drains, Karpenter re-evaluates the cluster, picks off empty or under-utilized nodes, and terminates them via its consolidation logic.
The payoff is speed and thrift. Nodes often appear in 30 to 45 seconds and disappear minutes after the last workload drains. Since its release, I’ve seen customers saying they got 25 to 40 percent savings just from bin-packing — and double that when Spot capacity is fair game.
Cluster Autoscaler Benefits#
I’m not here to crown a winner, but I do want to highlight a few points about CA to ultimately help you avoid rushing into Karpenter if you’re not ready yet or don’t need to right now.
First, let’s consider that — in reality — CA takes an infrastructure-first approach to scaling, which means you define your node infrastructure upfront and the autoscaler works within those predefined boundaries. This approach offers several distinct advantages:
- Granular control over scaling behavior: CA provides extensive configuration options that let you fine-tune exactly how scaling decisions are made. You can set different scale-down delay timers for different node groups, configure estimator types to optimize for bin-packing or least-waste strategies, and use expander policies to control which node groups scale first during high-demand periods (or mixing on-demand with Spot instances). This level of control is particularly valuable for those with strict change management processes.
- Battle-tested reliability: Let’s face it: Having been in production since 2016, CA has encountered and solved countless edge cases. Its conservative approach to scaling — i.e., waiting for configurable cooldown periods before making decisions — prevents the volatility that can occur when scaling too aggressively.
- Multi-cloud compatibility: CA's infrastructure-first design makes it naturally compatible with any cloud provider that supports node groups or auto-scaling groups. Whether you're running on AWS, GCP, Azure, or even on-premises Kubernetes distributions, CA can manage your scaling needs using the same familiar node group abstractions.
- Resource budget enforcement: By defining node groups with specific minimum and maximum sizes, CA provides hard limits on resource consumption. This makes it easier to enforce budget constraints or reserve capacity to access better compute prices. It also prevents runaway scaling scenarios that could lead to unexpected cloud bills.
Now, let’s turn our attention to Karpenter to see where it shines and to better understand how it’s different from CA.

Karpenter Benefits#
Karpenter takes an application-first approach where the workload constraints drive infrastructure decisions rather than the other way around. This fundamental shift in philosophy unlocks several powerful capabilities:
- Dynamic infrastructure selection: Instead of being constrained by predefined node groups, Karpenter evaluates each pod's resource requests, node selectors, affinity rules, and topology constraints then selects candidate instance types from the entire cloud catalog. When a pod requests 4 vCPUs and 8GB of memory, Karpenter might end up provisioning a c5.xlarge, m5.xlarge, or even an m6i.xlarge instance — depending on pricing and availability — all without requiring separate node groups for each possibility.
- Scheduler integration: Karpenter works in tandem with the Kubernetes scheduler, receiving unschedulable pods and using the same constraint-solving logic to determine which nodes to provision (not only how many as CA). This tight integration means that Karpenter understands not just resource requirements but also complex scheduling constraints like pod anti-affinity rules, topology spread constraints, and volume node affinity requirements, leading into launching efficient nodes. So, rather than scaling each node group independently, Karpenter can provision a single diverse node that accommodates multiple different workload types, leading to higher overall cluster efficiency.
- Real-time optimization: Because Karpenter doesn't rely on pre-provisioned node groups, it can reconsider nodes based on allocated resources. It simulates what would happen if pods are evicted to find out if better instance types could be launched. In other words, it could launch smaller or cheaper nodes or remove empty nodes by consolidating workloads onto more cost-effective instances as conditions change. Karpenter continuously evaluates whether existing nodes are optimally utilized and can automatically consolidate workloads onto fewer, more efficient nodes.
- **Simplified operational model: **The application-first approach means developers focus on defining their workload requirements in pod specifications while Karpenter handles the translation to infrastructure. Teams don't need to understand the intricacies of node group management; they simply specify CPU, memory, and scheduling constraints, and Karpenter provisions appropriate nodes.
The core difference lies in the mental model: CA asks, "What infrastructure do I want to manage?" while Karpenter asks, "What do my applications need?" This distinction makes CA ideal for organizations that prioritize infrastructure control and (some) predictability while Karpenter excels in environments where application agility and cost optimization are crucial.

Where DevZero Fits in the Autoscaling Landscape#
So far, we’ve looked at how Karpenter and CA approach the challenge of scaling Kubernetes clusters. But what if your scaling challenges go beyond node or pod scaling? That’s where DevZero enters the picture, offering a broader, more flexible approach to resource orchestration.
DevZero doesn’t just react to workload demands; it orchestrates resources across your entire stack, making it possible to scale at the cluster, node, and workload levels. For instance, DevZero uses machine learning to predict future workload needs, to then dynamically adjust CPU, memory, and even GPU allocations for individual conrtainers without restarts. Your applications get exactly what they need, when they need it, in real-time. Unlike traditional scaling that restarts workloads when moving them between nodes, DevZero uses a technology to snapshot running processes, preserving memory state, TCP connections, and filesystem state.
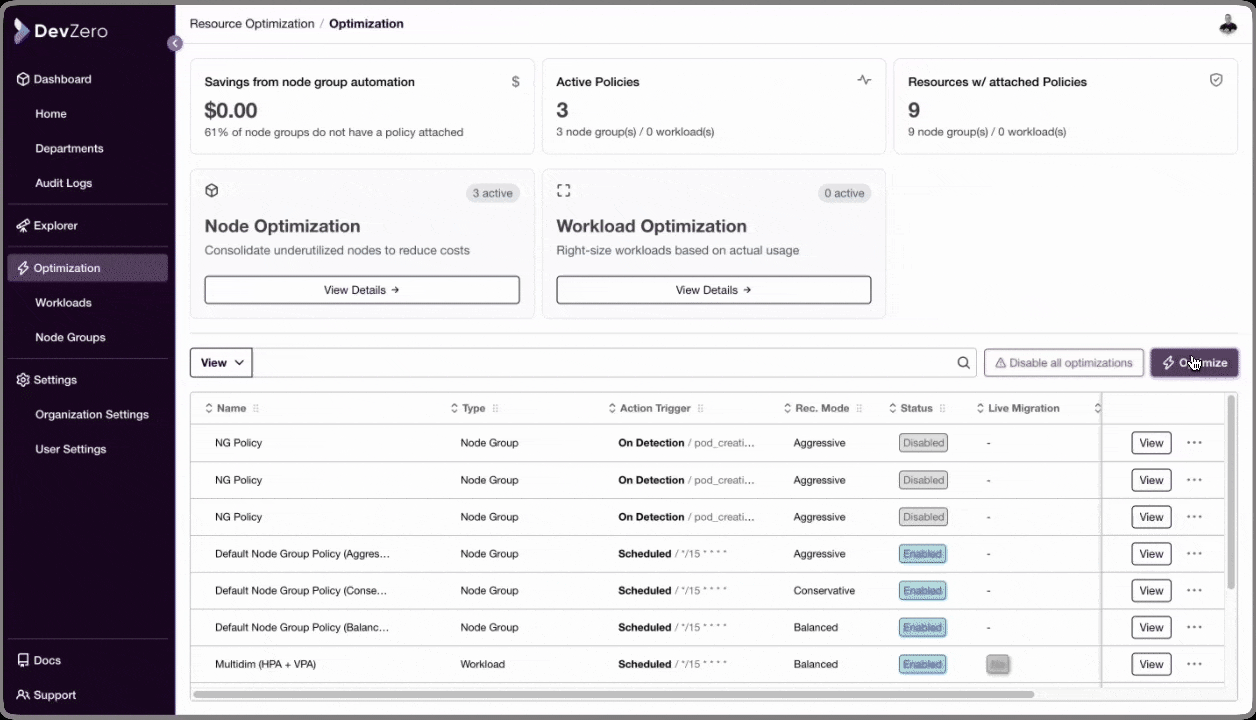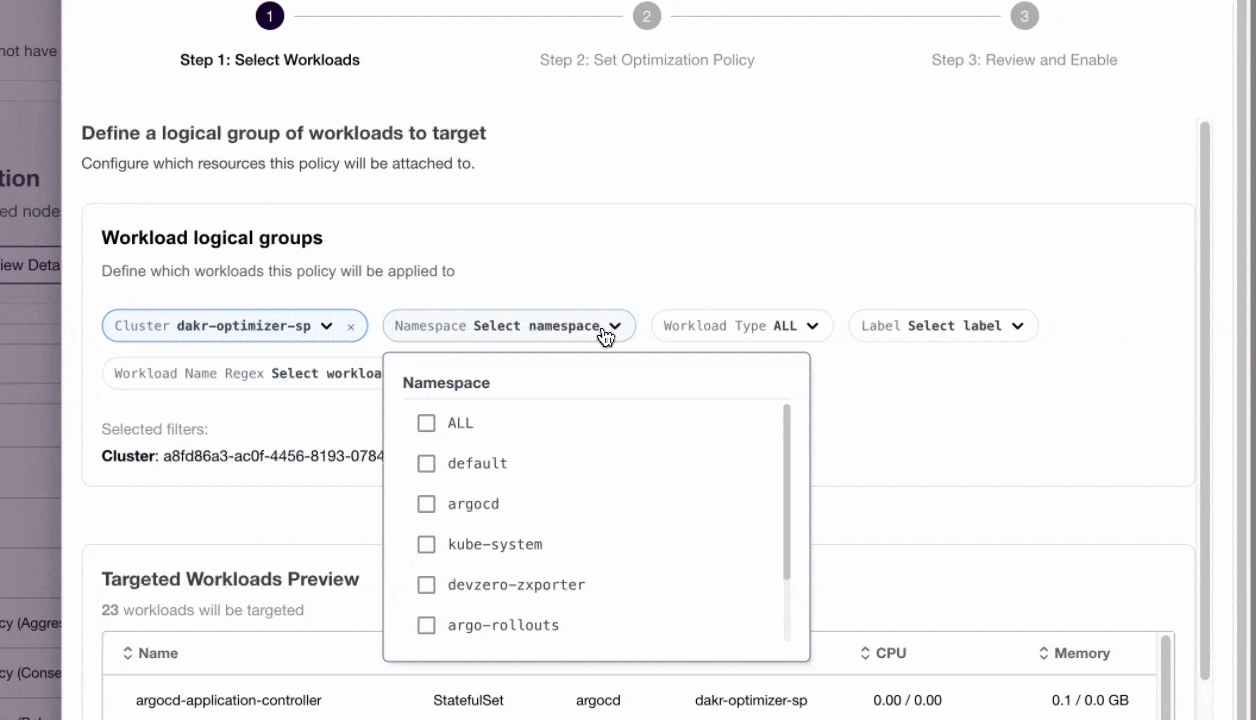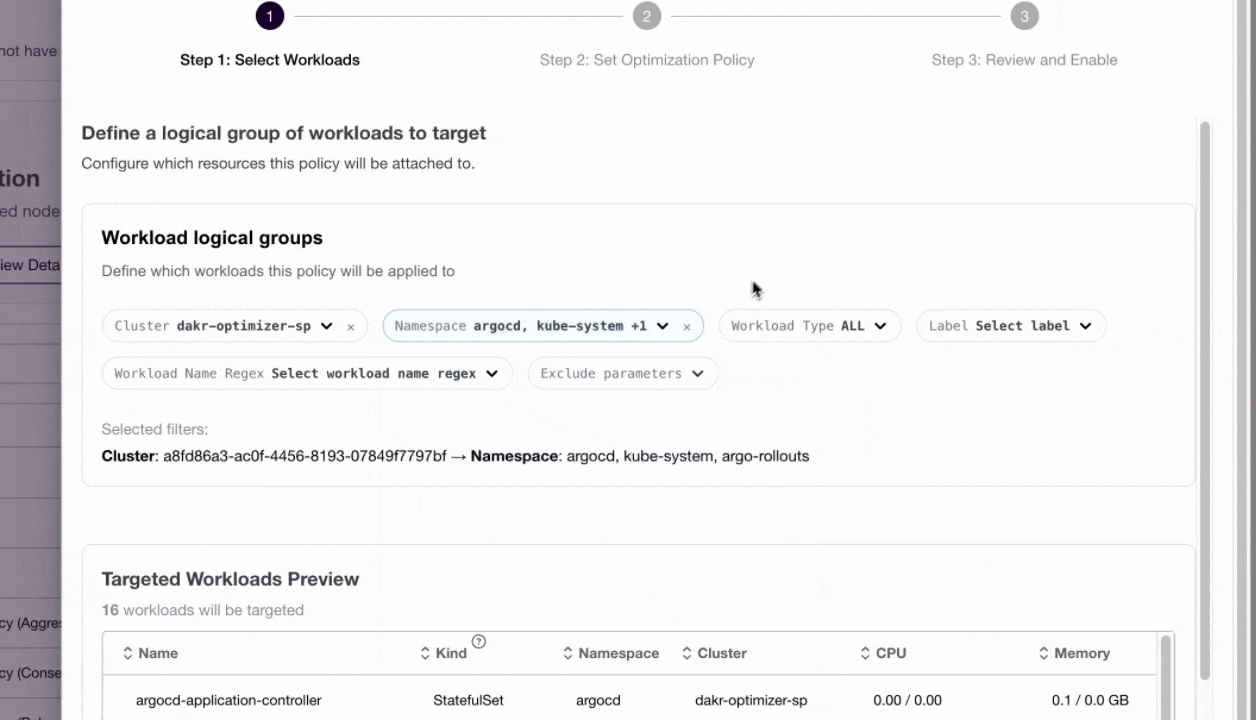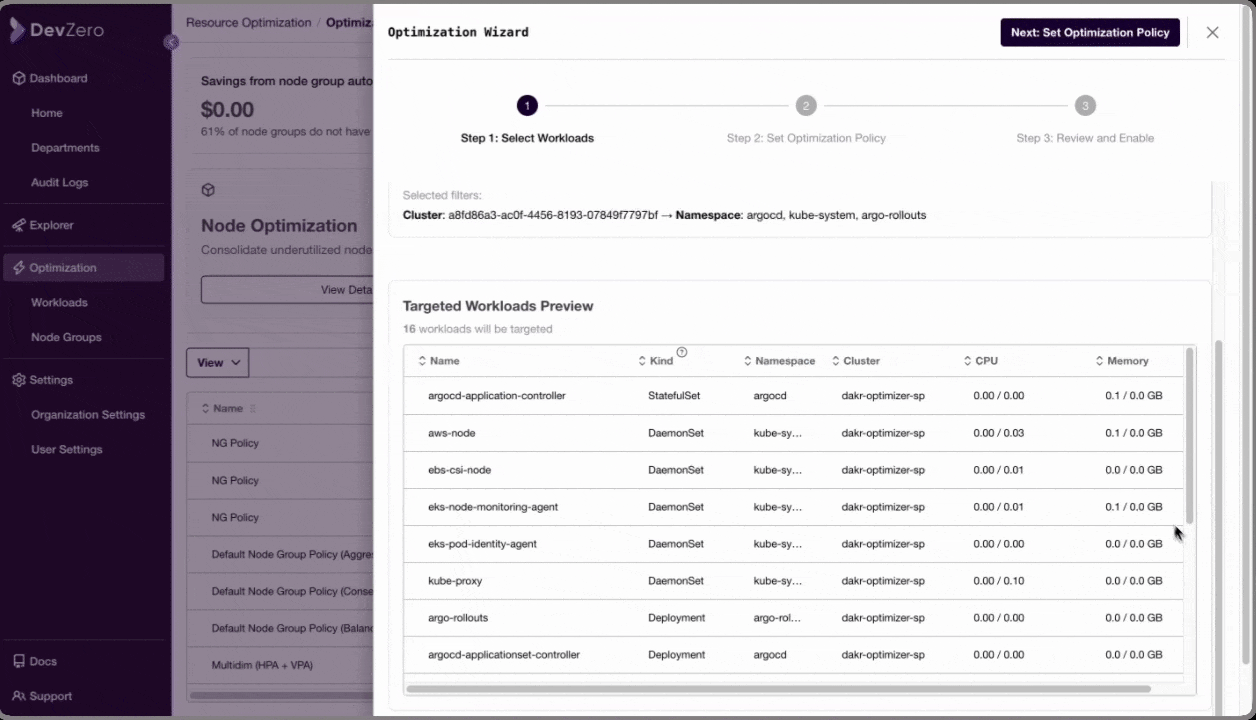
Defining granualr policies using DevZero
What really sets DevZero apart is its multi-cloud support and cost visibility. You’re not tied to a single cloud provider; DevZero orchestrates environments across AWS, Azure, GCP, and on-premises clusters — all from a single platform.
Here's more about what makes DevZero unique from other autoscalers.
Conclusion#
Karpenter and CA both deliver on the promise of efficient, automated scaling for Kubernetes clusters, but they approach the problem from fundamentally different angles.
CA is a good choice if you value predictable infrastructure, granular control, and multi-cloud compatibility. Its infrastructure-first model works well for organizations with strict requirements around node types and change management.
Karpenter, on the other hand, is built for teams that want to move fast and let application needs drive infrastructure decisions. Its application-first approach means less upfront configuration, more flexibility, and the ability to optimize for cost and performance in real time.
DevZero sits above both, orchestrating resources at the cluster, node, and workload levels. It brings multi-cloud support and live migration, enabling teams to seamlessly shift workloads between environments.
Ultimately, the best tool depends on your priorities: control and predictability, flexibility and efficiency, or broad orchestration and visibility.
To help you visualize these differences and give you a better idea of which tools might work best for your unique circumstances, here’s a comparison table:
| Feature | HPA | CA | Karpenter | DevZero |
|---|---|---|---|---|
| Scaling Layer | Workload-level | Node group (infrastructure-first) | Node (application-first) | Cluster, node (live migration), workload |
| Configuration Model | Target utilization thresholds | Predefined node groups | Flexible NodePool and workload-driven | Policy-driven, multi-level |
| Cloud Support | All Kubernetes distributions | All major providers | AWS (GA), GKE (GA or stable), Azure (preview support) | AWS, Azure, GCP, on-prem |
| Instance Diversity | N/A | Limited | Flexible | Any across clouds |
| Cost Optimization | You need to do right-sizing of pods | Bin-packing, scale-down knobs | Bin-packing, consolidation | User tracking |
| Policy Control | Pod level | Node group level | Node level | All levels |

Alberto Grande
Head of Marketing






